Implementation
Contents
Implementation#
Some code snippets are modified from [Shea, 2021] for my experimentation!
Utilities#
import sys
from pathlib import Path
parent_dir = str(Path().resolve().parent)
sys.path.append(parent_dir)
import random
import warnings
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
warnings.filterwarnings("ignore", category=DeprecationWarning)
%matplotlib inline
from utils import seed_all, true_pmf, empirical_pmf
seed_all(1992)
Using Seed Number 1992
The Setup#
We will use the same setup in Discrete Uniform Distribution but we will bump up the number from 1000 to 10000.
Let the true population be defined as a total of \(10000\) people. We talked about the height previously, and found out that the height of a person follows a uniform distribution.
Now, we cannot model the height as a Bernoulli distribution because if we use the same random variable \(X\) being the height of a randomly selected person from the true population, the Bernoulli distribution cannot be constructed because the state space of the distribution takes on a binary value by definition!
Our sample space for the height is of \(\{1, 2, \ldots, 10\}\), and the corresponding state space \(X(\S)\) is the same, consisting of 10 values. Bernoulli only allows \(X\) to take on two values/states, thus in our case, this condition has failed. However, if you ask a different question in terms of binary: What is the probability of the randomly selected person of taller than 5cm? Then this is a valid problem that can be modelled after the Bernoulli distribution, as we satisfy both conditions, one being that the state space has only 2 values (2 outcomes in sample space), the other being it is a single trial/experiment.
We will now use a more interesting setup, disease modelling.
Let the experiment be a triplet \(\pspace\), this experiment is the action of randomly selecting a person from the true population. This experiment can be denoted as a Bernoulli trial if we follow the assumptions of it.
Let us define \(Y\) to be the covid-status of a randomly selected person from the true population. Then \(Y\) has only two outcomes, “success” or “failure”.
Amongst the \(10000\) people, any person can only have 1 single status/outcome, either he/she has covid, or don’t. Thus, this can be treated as a Bernoulli distribution.
Since our problem is about the covid status of the person, we define our sample space to be \(\Omega = \{0, 1\}\), where \(0\) means no-covid and \(1\) means has-covid. And since we know the true population, we proceed to find out that there are 2000 people with covid, and 8000 without!
Now suppose I want to answer a few simple questions about the experiment. For example, I want to know
What is the probability of selecting a person with covid?
What is the expected value of the true population?
Since we have defined \(Y\) earlier, the corresponding state space \(Y(\S)\) is also \(\{0, 1\}\). We can associate each state \(y \in Y(\S)\) with a probability \(P(Y = y)\). This is the probability mass function (PMF) of \(Y\).
and we seek to find \(p\), and since we already know the true population (\(p=0.2\)), we can plot an ideal histogram to see the distribution of how the covid-status of each person in the true population is distributed. An important reminder is that in real world, we often won’t know the true population, and therefore estimating/inferencing the \(p\) parameter becomes important.
The PMF (Ideal Histogram)#
# create a true population of 10000 people of 2000 1s and 8000 0s
true_population = np.zeros(shape=10000)
true_population[:2000] = 1
def plot_true_pmf(population: np.ndarray):
"""Plots the PMF of the true population."""
bins = np.arange(0, population.max() + 1.5) - 0.5
fig, ax = plt.subplots()
_ = ax.hist(
population,
bins,
density=True,
color="#0504AA",
alpha=0.5,
edgecolor="black",
linewidth=2,
)
_ = ax.stem(
population,
[true_pmf(x, population) for x in population],
linefmt="C3-",
markerfmt="C3o",
basefmt="C3-",
use_line_collection=True,
)
_ = ax.set_xlabel("Covid Status")
_ = ax.set_ylabel("Probability")
_ = ax.set_title("PMF of the true population")
_ = ax.set_xticks(bins + 0.5)
#ax.set_xticklabels(["Negative", "Positive"])
return fig, ax
_ = plot_true_pmf(true_population)
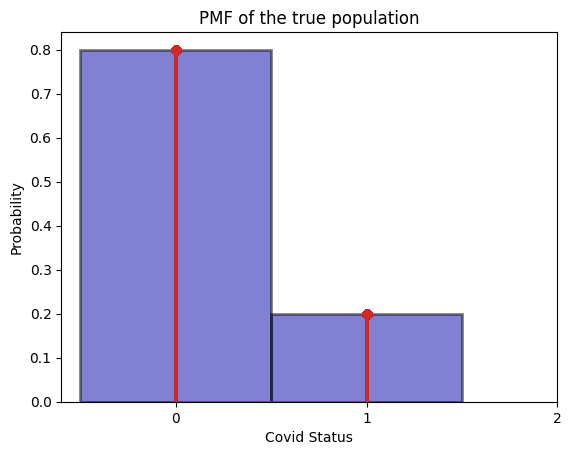
The true pmf (ideal histogram) gives the answer that out of the true population, \(80\%\) has no covid, and \(20\%\) has covid.
So our PMF is realized:
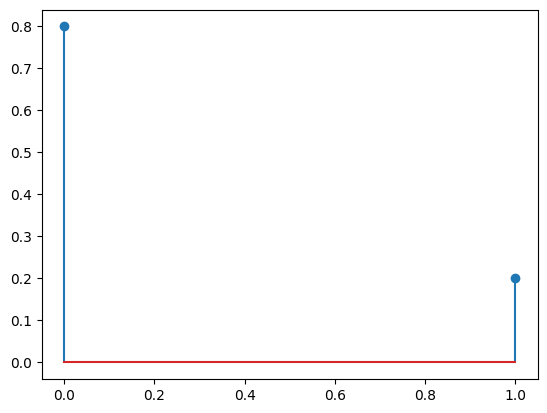
We can test it with stats.bernoulli.
p = 0.2
# `Y` is now an object that represents a Bernoulli random variable with parameter $p=0.2$.
Y = stats.bernoulli(0.2)
y = np.asarray([0, 1]) # {0, 1}
f = Y.pmf(y)
print(f)
[0.8 0.2]
plt.stem(y, f, use_line_collection=True);
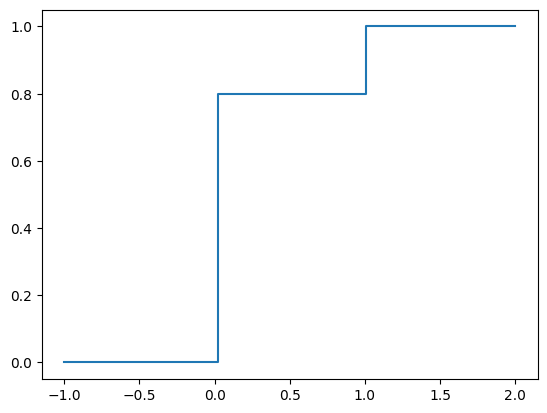
The CDF is plotted below.
y = np.linspace(-1, 2, 101)
F = Y.cdf(y)
plt.step(y, F, where="post");
Empirical Distribution (Empirical Histograms)#
We are often given datasets from our stakeholders, be it 100 data points or 900 data points, we will not know if this number is truly close to our true population.
But we want to prove a point, the convergence theory that if you have sufficiently large samples, then your empirical histogram/distribution will tend to the true distribution/PMF. See [and, 2022].
Let us draw samples of 1000, 5000 and 9000 to get the relative frequencies, and see if it indeed converges to our true distribution:
# FIXME: unsure if replace=True or False here, but I read they are independent so it should be with replacement.
sample_1000 = np.random.choice(true_population, 1000, replace=True)
sample_5000 = np.random.choice(true_population, 5000, replace=True)
sample_9000 = np.random.choice(true_population, 9000, replace=True)
counter = 0
for i in sample_1000:
if i == 0:
counter += 1
print(counter) # ok surprisingly quite close..
795
# ideal + empirical
fig, axs = plt.subplots(2, 2, figsize=(20, 10))
bins = np.arange(0, true_population.max() + 1.5) - 0.5
axs[0, 0].hist(
true_population,
bins,
density=True,
color="#0504AA",
alpha=0.5,
edgecolor="black",
linewidth=2,
)
axs[0, 0].stem(
true_population,
[true_pmf(x, true_population) for x in true_population],
linefmt="C3-",
markerfmt="C3o",
basefmt="C3-",
use_line_collection=True,
)
axs[0, 0].set_title("PMF of the true population")
axs[0, 0].set_xlabel("Covid Status")
axs[0, 0].set_ylabel("Probability")
axs[0, 0].set_xticks(bins + 0.5)
axs[0, 1].hist(
sample_1000,
bins,
density=True,
color="#0504AA",
alpha=0.5,
edgecolor="black",
linewidth=2,
)
axs[0, 1].stem(
sample_1000,
[empirical_pmf(x, sample_1000) for x in sample_1000],
linefmt="C3-",
markerfmt="C3o",
basefmt="C3-",
use_line_collection=True,
)
axs[0, 1].set_title("PMF of a sample of size 1000")
axs[0, 1].set_xlabel("Covid Status")
axs[0, 1].set_ylabel("Probability")
axs[0, 1].set_xticks(bins + 0.5)
axs[1, 0].hist(
sample_5000,
bins,
density=True,
color="#0504AA",
alpha=0.5,
edgecolor="black",
linewidth=2,
)
axs[1, 0].stem(
sample_5000,
[empirical_pmf(x, sample_5000) for x in sample_5000],
linefmt="C3-",
markerfmt="C3o",
basefmt="C3-",
use_line_collection=True,
)
axs[1, 0].set_title("PMF of a sample of size 5000")
axs[1, 0].set_xlabel("Covid Status")
axs[1, 0].set_ylabel("Probability")
axs[1, 0].set_xticks(bins + 0.5)
axs[1, 1].hist(
sample_9000,
bins,
density=True,
color="#0504AA",
alpha=0.5,
edgecolor="black",
linewidth=2,
)
axs[1, 1].stem(
sample_9000,
[empirical_pmf(x, sample_9000) for x in sample_9000],
linefmt="C3-",
markerfmt="C3o",
basefmt="C3-",
use_line_collection=True,
)
axs[1, 1].set_title("PMF of a sample of size 9000")
axs[1, 1].set_xlabel("Covid Status")
axs[1, 1].set_ylabel("Probability")
axs[1, 1].set_xticks(bins + 0.5);
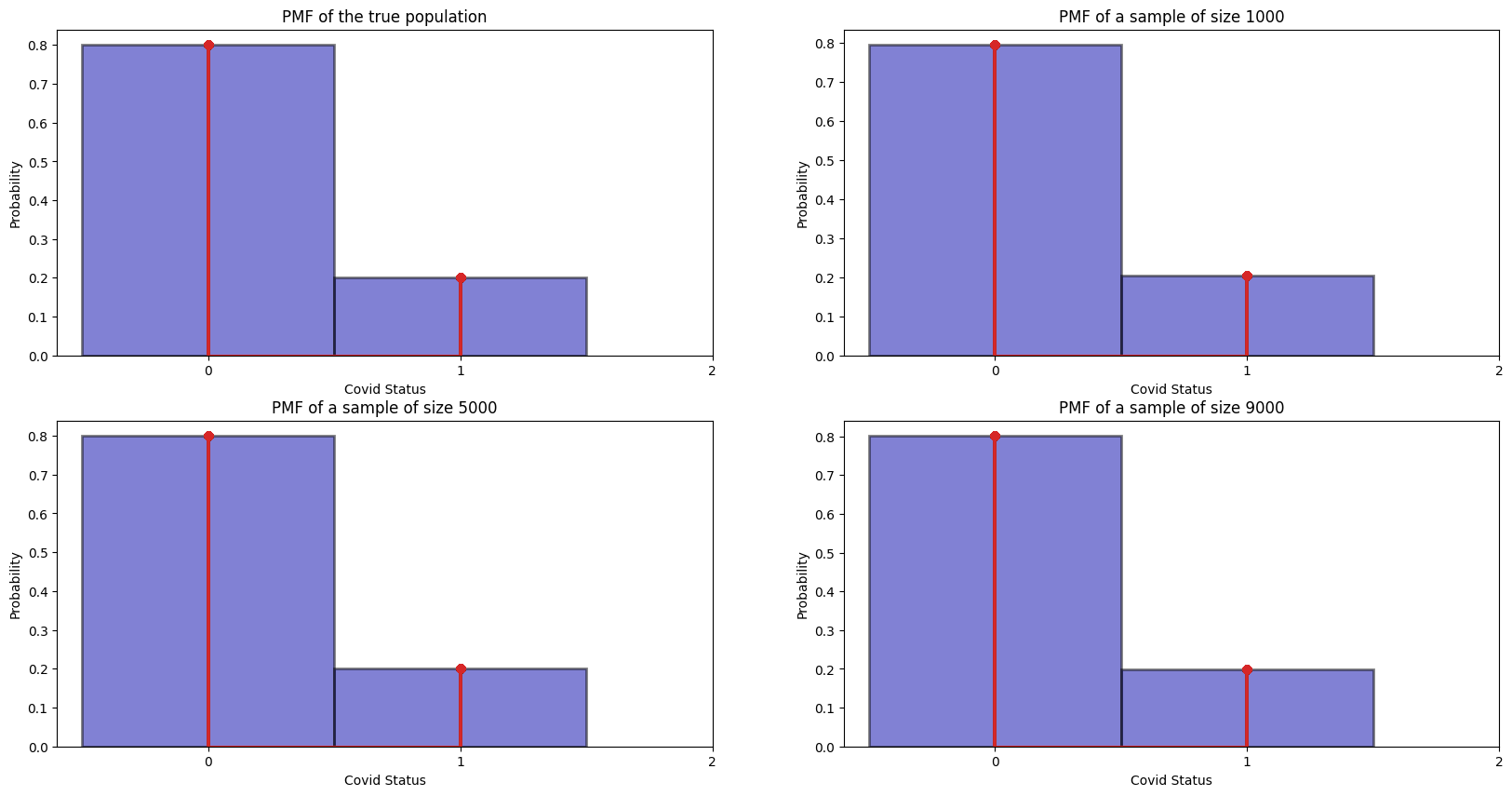
It is quite clear that as number of samples go up, the empirical histograms become more accurate. This is not surprisingly as intuitively, as your samples become large, your distribution will be more accurate to the true population.
Okay maybe not so clear as all 3 looks quite close :(
We can use scipy.stats as its random variables also has the ability to draw random values from the specified distribution (i.e., to get values of the random variable).
The method to do this is called rvs. If it is called with no argument, then it generates a single value of that random variable [Shea, 2021].
Y.rvs() # 1 sample
0
Y.rvs(size=10) # 10 samples from the distribution
array([0, 1, 1, 0, 0, 0, 0, 0, 0, 0])
In our case, we can do the same, 1000, 5000 and 9000 and plot them compared to the true distribution.
num_sims = 1000
y = Y.rvs(num_sims)
counts = np.asarray([list(y).count(0), list(y).count(1)]) # how many no covid vs covid
print(f"The relative freqs are {counts/num_sims}")
plt.bar([0, 1], counts / num_sims, alpha=0.5)
plt.stem([0, 1], Y.pmf([0, 1]), linefmt="orange", use_line_collection=True);
The relative freqs are [0.821 0.179]
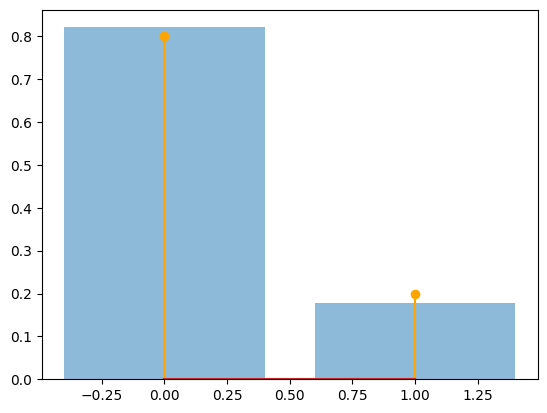
num_sims = 5000
y = Y.rvs(num_sims)
counts = np.asarray([list(y).count(0), list(y).count(1)]) # how many no covid vs covid
print(f"The relative freqs are {counts/num_sims}")
plt.bar([0, 1], counts / num_sims, alpha=0.5)
plt.stem([0, 1], Y.pmf([0, 1]), linefmt="orange", use_line_collection=True);
The relative freqs are [0.8018 0.1982]
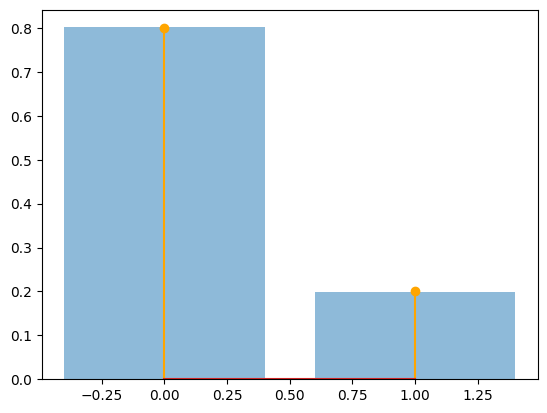
num_sims = 9000
y = Y.rvs(num_sims)
counts = np.asarray([list(y).count(0), list(y).count(1)]) # how many no covid vs covid
print(f"The relative freqs are {counts/num_sims}")
plt.bar([0, 1], counts / num_sims, alpha=0.5)
plt.stem([0, 1], Y.pmf([0, 1]), linefmt="orange", use_line_collection=True);
The relative freqs are [0.79922222 0.20077778]
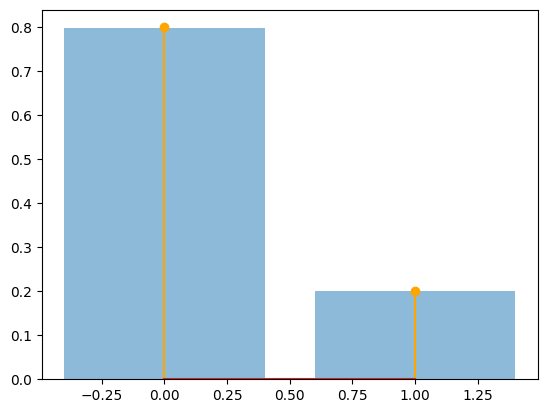
Bernoulli Sampling#
One way is sample with replacement so samples are independent, but if sample size is large enough, sample without also converges.
Logistic Regression#
The Bernoulli distribution can be used to model the response of a logistic regression model conditionally. For example, let \(Y\) be 0 or 1, denoting if a person has covid. The predictors is the height and weight of the person. Then \(Y(y=1 | X = x)\) follows a Bernoulli distribution (conditional).