Exercises
Contents
Exercises#
1import os
2import random
3import string
4from typing import *
5
6import matplotlib.pyplot as plt
7import numpy as np
8from numpy.random import default_rng
9
10# from functools import cache # 3.9
1%cd ..
2
3from utils import seed_all
/home/runner/work/gaohn-probability-stats/gaohn-probability-stats/content
Consider one day to code up random generators like Uniform Distribution from scratch:
https://github.com/neerajkumarvaid/Data-Science-From-Scratch-Python/blob/master/probability.py
Question 6#
1def f(x, y):
2 return np.divide(1, np.multiply(2 * np.sqrt(3), np.pi)) * np.exp(
3 np.multiply(
4 np.divide(-1, 6),
5 (x ** 2 - 2 * x * y - 2 * x + 4 * y ** 2 + 2 * y + 1),
6 )
7 )
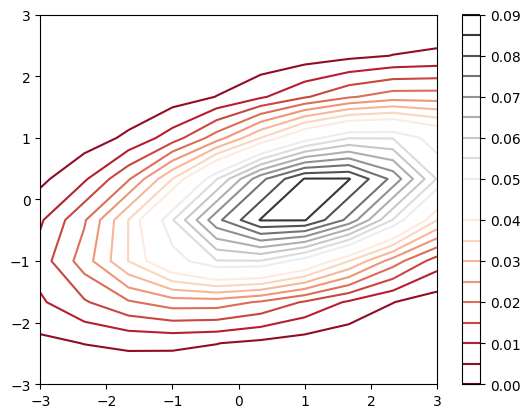
Create meshgrids such that we enumerate cases of the range \([-3, 3] \times [-3, 3]\) for the values that \(X\) and \(Y\) can take on. Correspondingly, set \(Z = f(X, Y)\) such that we have constant values for the set of values we got from the meshgrid.
As an example:
When \(X = -3, Y = 3\), we have \(Z = f(X, Y) = 2.8986519194402697e-07\). This is one contour line in the 2d space, but why it looks like a curvature (circle)? This suggests that when keeping \(Z\) to be the constant of \(2.8986519194402697e-07\), there are many different set of \((X, Y)\) that gives this value!
1X = np.linspace(-3, 3, 10)
2Y = np.linspace(-3, 3, 10)
3X, Y = np.meshgrid(X, Y)
4Z = f(X, Y)
5plt.contour(X, Y, Z, 20, cmap='RdGy')
6plt.colorbar();
Question 9#
1# @lru_cache
2def calc_vowel_consonant_prob(
3 num_simulations: int,
4 letters: List[str],
5 vowels: List[str],
6 consonants: List[str],
7 *args,
8 **kwargs,
9) -> float:
10 """A collection of 26 English letters, a-z, is mixed in a jar. Two letters are drawn at random,
11 one after the other without replacement. What is the probability of drawing a vowel (a,e,i,o,u)
12 and a consonant in either order?
13
14 Args:
15 num_simulations (int): Number of simulations to run.
16 letters (List[str]): List of letters.
17 vowels (List[str]): List of vowels.
18 consonants (List[str]): List of consonants.
19
20 Returns:
21 (float): The probability of drawing a vowel and a consonant in either order.
22 """
23 count = 0
24 rng = default_rng()
25
26 letters = np.asarray(letters)
27
28 for _ in range(num_simulations):
29 sample_2_letters_without_replacement = rng.choice(*args, **kwargs)
30 chosen_letters = letters[sample_2_letters_without_replacement]
31 if not (
32 set(chosen_letters).issubset(vowels)
33 or set(chosen_letters).issubset(consonants)
34 ):
35 count += 1
36
37 return count / num_simulations
1all_letters = list(string.ascii_lowercase)
2vowels = ["a", "e", "i", "o", "u"]
3consonants = list(set(all_letters) - set(vowels))
4
5num_simulations = 1000000
6calc_vowel_consonant_prob(num_simulations, all_letters, vowels, consonants, a=26, size=2, replace=False)
0.323415
sample_2_letters_without_replacement = rng.choice(a = 26, size = 2, replace=False): This is equivalent torandom.sample(range(26), 2)which if we set the parameters correctly, means we will sample index 0 to 25 twice, without replacement. For example, the sampled index is in a form of a array of size 2:[1, 4]which corresponds to the letters[b, e].Note in particular this sampling is a using a uniform distribution where each letter has \(\frac{1}{26}\) chance of getting selected in the first sample.
chosen_letters = np.asarray(all_letters)[sample_2_letters_without_replacement]: This is just subsetting the index from theall_letters. Sinceall_lettersis a list which enumerates the alphabets in order, it suffices for us to just subset the array directly to get the chosen letters.if not (set(chosen_letters).issubset(vowels) or set(chosen_letters).issubset(consonant)): count += 1: If ourchosen_lettersis neither a subset of the vowels or the consonant, then this means that it fulfills our condition, (i.e. one consonant and one vowel, we don’t care order since the question said either order). If condition fulfilled,countadds 1.Lastly, calculate the probability by dividing the
countby thenum_simulationsto get the frequency (i.e the probability). Indeed with enough simulations, the probability converges to the theoretical answer of \(0.3230...\).
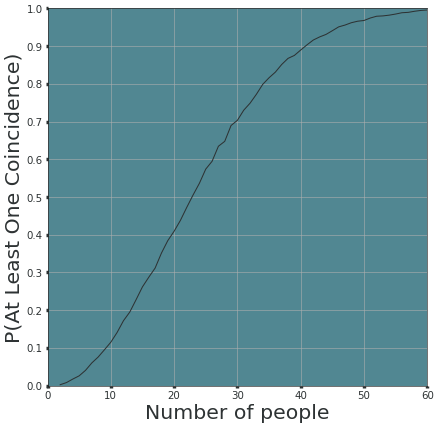
Question 10: Birthday Paradox#
Settings:
50 people
Assume each person has a \(\frac{1}{365}\) probability to be assigned a birthday. In other words, the person’s birthday should come from a uniform distribution from 1 to 365.
So simple modelling just allows us to draw numbers for these 50 people from \([1, 365]\) and whenever the number is same we say they are of the same birthday.
Want to find probability (frequency) of at least 2 people have same birthday.
Note that in your code one should also consider any number \(>=2\).
1rng = np.random.default_rng()
2num_possible_birthdays = 365
3num_people = 50
4num_simulations = 1000
1def containsDuplicate(nums: List[int]) -> bool:
2 """Check if a list contains duplicate elements.
3
4 Args:
5 nums (List[int]): List of integers.
6
7 Returns:
8 bool: Boolean value to indicate if the list contains duplicate elements.
9 """
10 dup_dict = {}
11
12 for _, num in enumerate(nums):
13 if num not in dup_dict:
14 dup_dict[num] = 0
15 else:
16 return True
17 return False
1def generate_one_random_birthday(num_possible_birthdays: int = 365) -> int:
2 """Generate one random birthday from 1 to num_possible_birthdays.
3
4 Samples 1 integer from 1 to 365 from a uniform distribution.
5
6 Args:
7 num_possible_birthdays (int): The number of possible birthdays. Defaults to 365.
8
9 Returns:
10 birthday (int): The random birthday in integer.
11 """
12 # Return random integers from the "discrete uniform" distribution of the specified dtype. If high is None (the default), then results are from 0 to low.
13 birthday = rng.integers(num_possible_birthdays, size=None) # size=None to return integer instead of array of ints
14 return birthday
1def generate_k_birthdays(
2 num_people: int, *args, **kwargs
3) -> List[int]:
4 """Generates all possible birthdays for a given number of people sampled
5 from a uniform distribution.
6
7 Example:
8 If there are 3 people, the possible birthdays can be understood to be sampled from a uniform distribution
9 of 1 to 365 inclusive with replacement.
10 >>> generate_k_birthdays(3, 365)
11
12 Args:
13 num_people (int): The number of people in the group.
14 num_possible_birthdays (int, optional): Number of possible birthdays. Defaults to 365.
15
16 Returns:
17 birthdays (List[int]): A list of birthdays.
18
19 """
20
21 birthdays = [
22 generate_one_random_birthday(*args, **kwargs)
23 for _ in range(num_people)
24 ]
25 return birthdays
1def calculate_same_birthday_probability(
2 num_simulations: int, *args, **kwargs
3) -> float:
4 """Calculates the probability of the Birthday Paradox Problem.
5
6 Args:
7 num_simulations (int, optional): The number of simulations to run.
8
9 Returns:
10 probability (float): The probability of the Birthday Paradox.
11 """
12 count = 0
13 for _ in range(num_simulations):
14 birthdays = generate_k_birthdays(*args, **kwargs)
15 if containsDuplicate(birthdays):
16 count += 1
17
18 probability = count / num_simulations
19 return probability
1calculate_same_birthday_probability(num_simulations=10000, num_people=50, num_possible_birthdays=365)
0.9706
We go through one loop of the simulation to understand the code:
birthdays = default_rng().choice(a=num_possible_birthdays, size=num_people, replace=True): what this does is two folds,Samples 1 integer from 1 to 365 from a uniform distribution. (i.e. 1 to num_possible_birthdays)
Repeat the sampling of 1 integer 50 times. (i.e. num_people=50)
In short, it returns an array of 50 elements, each element is sampled uniformly from 1 to 365 inclusive.
if has_duplicates(birthdays)checks whether the array has duplicates (i.e. akin to checking if 2 or more people has the same birthdays).If
True,count +=1.
Finally, the probability is the number of
countdivided by the total number of simulations. It should converge to around \(0.97\).One should realize by now probability in most parts, is just the frequency of “occurring” over the total number of “events”.
1def calculate_same_birthday_probability_rng_choice(
2 num_simulations: int,
3 num_people: int = 50,
4 num_possible_birthdays: int = 365,
5 replace: bool = True,
6) -> float:
7 """Calculates the probability of the Birthday Paradox Problem.
8
9 Args:
10 num_simulations (int, optional): The number of simulations to run.
11 num_people (int, optional): The number of people in the simulation.
12 num_possible_birthdays (int, optional): The number of possible birthdays.
13 replace (bool, optional): Whether or not to sample with replacement.
14
15 Returns:
16 probability (float): The probability of the Birthday Paradox.
17 """
18 count = 0
19 for _ in range(num_simulations):
20 birthdays = default_rng().choice(
21 a=num_possible_birthdays, size=num_people, replace=True
22 )
23 if containsDuplicate(birthdays):
24 count += 1
25
26 probability = count / num_simulations
27 return probability
1calculate_same_birthday_probability_rng_choice(num_simulations=10000, num_people=50, num_possible_birthdays=365, replace=True)
0.9683
The below code is not mine and is taken from here. For my reference to see if I coded correctly.
1from random import randint
2
3import matplotlib.pyplot as plt
4import seaborn as sns
5
6MIN_NUM_PEOPLE = 2
7MAX_NUM_PEOPLE = 60
8NUM_POSSIBLE_BIRTHDAYS = 365
9NUM_TRIALS = 10000
10
11def generate_random_birthday():
12 birthday = randint(1, NUM_POSSIBLE_BIRTHDAYS)
13 return birthday
14
15def generate_k_birthdays(k):
16 birthdays = [generate_random_birthday() for _ in range(k)]
17 return birthdays
18
19def aloc(birthdays):
20 unique_birthdays = set(birthdays)
21
22 num_birthdays = len(birthdays)
23 num_unique_birthdays = len(unique_birthdays)
24 has_coincidence = (num_birthdays != num_unique_birthdays)
25
26 return has_coincidence
27
28def estimate_p_aloc(k):
29 num_aloc = 0
30 for _ in range(NUM_TRIALS):
31 birthdays = generate_k_birthdays(k)
32 has_coincidence = aloc(birthdays)
33 if has_coincidence:
34 num_aloc += 1
35
36 p_aloc = num_aloc / NUM_TRIALS
37 return p_aloc
38
39def estimate_p_aloc_for_range(ks):
40 k_probabilities = []
41
42 for k in ks:
43 p_aloc = estimate_p_aloc(k)
44 k_probabilities.append(p_aloc)
45
46 return k_probabilities
47
48ks = range(MIN_NUM_PEOPLE, MAX_NUM_PEOPLE + 1)
49k_probabilities = estimate_p_aloc_for_range(ks)
50
51fig, ax = plt.subplots(figsize=(10, 10), dpi=49)
52ax.set_facecolor('#518792')
53ax.xaxis.set_tick_params(width=5, color='#2d3233')
54ax.yaxis.set_tick_params(width=5, color='#2d3233')
55
56sns.lineplot(x=ks, y=k_probabilities, color='#2d3233')
57
58plt.xticks(fontsize=15, color='#2d3233')
59y_range = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
60plt.yticks(y_range, fontsize=15, color='#2d3233')
61plt.grid()
62plt.xlim([0, 60])
63plt.ylim([0, 1])
64plt.xlabel('Number of people', fontsize=30, color='#2d3233')
65plt.ylabel('P(At Least One Coincidence)', fontsize=30, color='#2d3233')
66
67plt.show()